

在模式识别领域中,最近邻居法(KNN算法,又译K-近邻算法)是一种用于分类和回归的非参数统计方法。1最近邻居法采用向量空间模型来分类,概念为相同类别的案例,彼此的相似度高,而可以借由计算与已知类别案例之相似度,来评估未知类别案例可能的分类。
简介最近邻居法是一种基于实例的学习,或者是局部近似和将所有计算推迟到分类之后的惰性学习。k-近邻算法是所有的机器学习算法中最简单的之一。
无论是分类还是回归,衡量邻居的权重都非常有用,使较近邻居的权重比较远邻居的权重大。例如,一种常见的加权方案是给每个邻居权重赋值为1/ d,其中d是到邻居的距离。
邻居都取自一组已经正确分类(在回归的情况下,指属性值正确)的对象。虽然没要求明确的训练步骤,但这也可以当作是此算法的一个训练样本集。
最简单最初级的分类器是将全部的训练数据所对应的类别都记录下来,当测试对象的属性和某个训练对象的属性完全匹配时,便可以对其进行分类。但是怎么可能所有测试对象都会找到与之完全匹配的训练对象呢,其次就是存在一个测试对象同时与多个训练对象匹配,导致一个训练对象被分到了多个类的问题,基于这些问题呢,就产生了KNN。
KNN是通过测量不同特征值之间的距离进行分类。它的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别,其中K通常是不大于20的整数。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
下面通过一个简单的例子说明一下:如下图,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。
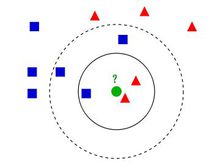
由此也说明了KNN算法的结果很大程度取决于K的选择。
在KNN中,通过计算对象间距离来作为各个对象之间的非相似性指标,避免了对象之间的匹配问题,在这里距离一般使用欧氏距离或曼哈顿距离:
欧式距离: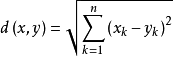
曼哈顿距离: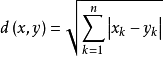
同时,KNN通过依据k个对象中占优的类别进行决策,而不是单一的对象类别决策。这两点就是KNN算法的优势。
流程介绍在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对应的特征进行相互比较,找到训练集中与之最为相似的前K个数据,则该测试数据对应的类别就是K个数据中出现次数最多的那个分类,其算法的描述为:
1)计算测试数据与各个训练数据之间的距离;
2)按照距离的递增关系进行排序;
3)选取距离最小的K个点;
4)确定前K个点所在类别的出现频率;
5)返回前K个点中出现频率最高的类别作为测试数据的预测分类。
参数选择如何选择一个最佳的K值取决于数据。一般情况下,在分类时较大的K值能够减小噪声的影响,2但会使类别之间的界限变得模糊。一个较好的K值能通过各种启发式技术来获取。
噪声和非相关性特征的存在,或特征尺度与它们的重要性不一致会使K近邻算法的准确性严重降低。对于选取和缩放特征来改善分类已经作了很多研究。一个普遍的做法是利用进化算法优化功能扩展,还有一种较普遍的方法是利用训练样本的互信息进行选择特征。
在二元(两类)分类问题中,选取k为奇数有助于避免两个分类平票的情形。在此问题下,选取最佳经验k值的方法是自助法。
属性原始朴素的算法通过计算测试点到存储样本点的距离是比较容易实现的,但它属于计算密集型的,特别是当训练样本集变大时,计算量也会跟着增大。多年来,许多用来减少不必要距离评价的近邻搜索算法已经被提出来。使用一种合适的近邻搜索算法能使K近邻算法的计算变得简单许多。
近邻算法具有较强的一致性结果。随着数据趋于无限,算法保证错误率不会超过贝叶斯算法错误率的两倍。对于一些K值,K近邻保证错误率不会超过贝叶斯的。
决策边界近邻算法能用一种有效的方式隐含的计算决策边界。另外,它也可以显式的计算决策边界,以及有效率的这样做计算,使得计算复杂度是边界复杂度的函数。3
连续变量估计K近邻算法也适用于连续变量估计,比如适用反距离加权平均多个K近邻点确定测试点的值。该算法的功能有:
从目标区域抽样计算欧式或马氏距离;
在交叉验证后的RMSE基础上选择启发式最优的K邻域;
计算多元k-最近邻居的距离倒数加权平均。
发展然而k最近邻居法因为计算量相当的大,所以相当的耗时,Ko与Seo提出一算法TCFP(textcategorization usingfeatureprojection),尝试利用特征投影法来降低与分类无关的特征对于系统的影响,并借此提升系统性能,其实验结果显示其分类效果与k最近邻居法相近,但其运算所需时间仅需k最近邻居法运算时间的五十分之一。
除了针对文件分类的效率,尚有研究针对如何促进k最近邻居法在文件分类方面的效果,如Han等人于2002年尝试利用贪心法,针对文件分类实做可调整权重的k最近邻居法(weightedadjustedk****nearestneighbor),以促进分类效果;而Li等人于2004年提出由于不同分类的文件本身有数量上有差异,因此也应该依照训练集合中各种分类的文件数量,选取不同数目的最近邻居,来参与分类。
本词条内容贡献者为:
宋春霖 - 副教授 - 江南大学
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国